Role:
Product Strategist, & Product Designer
Date:
Mar 2021
Problem
In the high-stakes arena of pharmaceutical innovation, time is measured not in hours, but in lives potentially saved or lost. Early 2021 presented me and my team with a challenge that would test the boundaries of technological innovation and strategic thinking: partnering with a pharmaceutical titan to dismantle the seemingly impenetrable walls of clinical trial inefficiency.
The drug development lifecycle—a labyrinthine journey from scientific discovery to life-saving treatment—had become a complex maze of delays, where promising medical breakthroughs languished in bureaucratic gridlock. Our mandate was audacious yet crystal clear: deconstruct a process that had remained virtually unchanged for decades, and reimagine how pieces of emerging technology could dramatically compress timelines without compromising scientific rigor.
At the heart of this challenge lay an intricate ecosystem of data, discovery, and human potential. The exploration phase alone was a microcosm of complexity—a sophisticated dance of mapping data sources, identifying missing links, evaluating biological target groups, and navigating the intricate landscape of patterns and correlations.
We weren't just solving a technological problem; we were reimagining the very fabric of medical innovation.
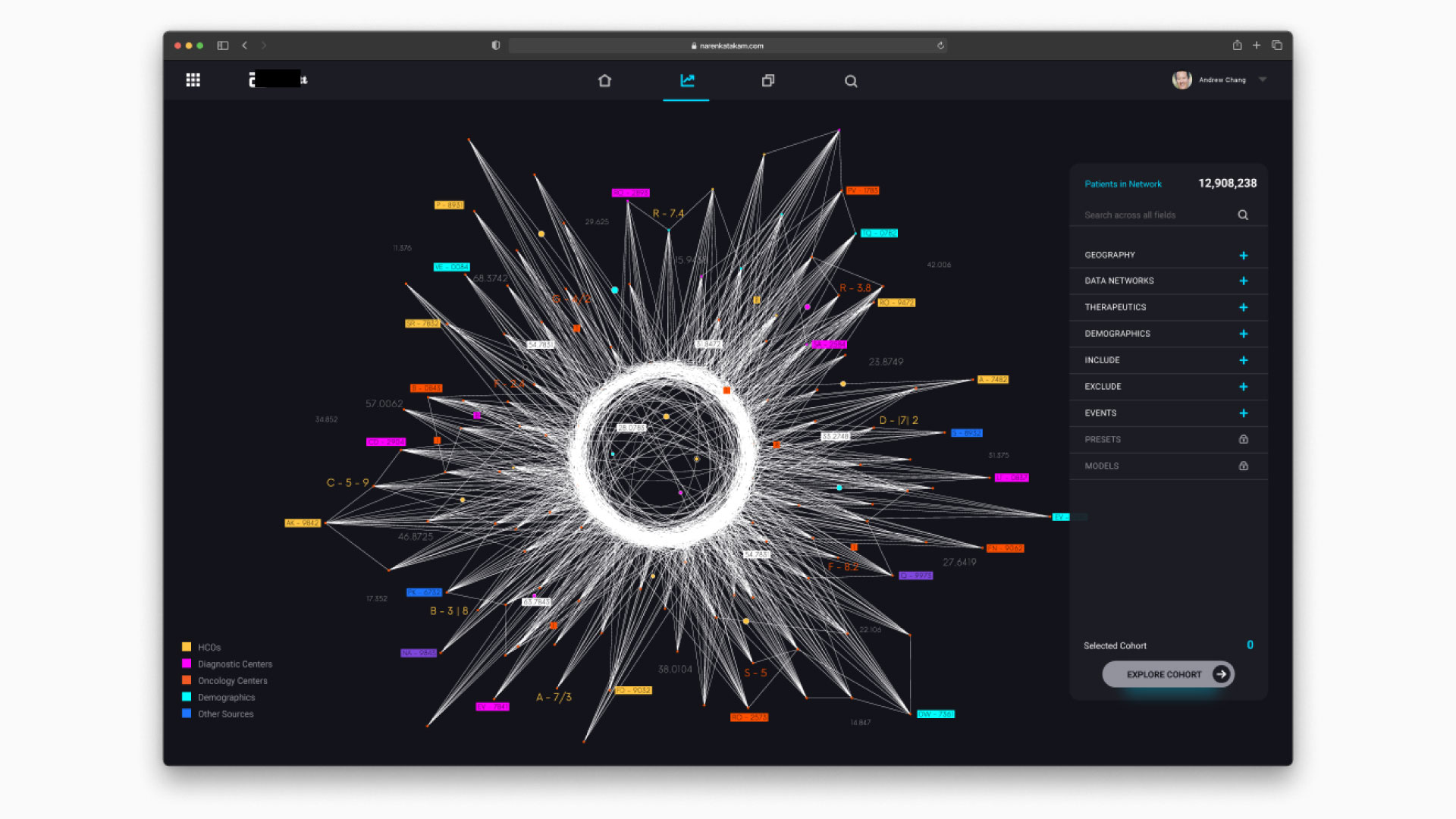
How data, AI & digital twin can help in drug discovery & slash clinical trial timelines?
Approach
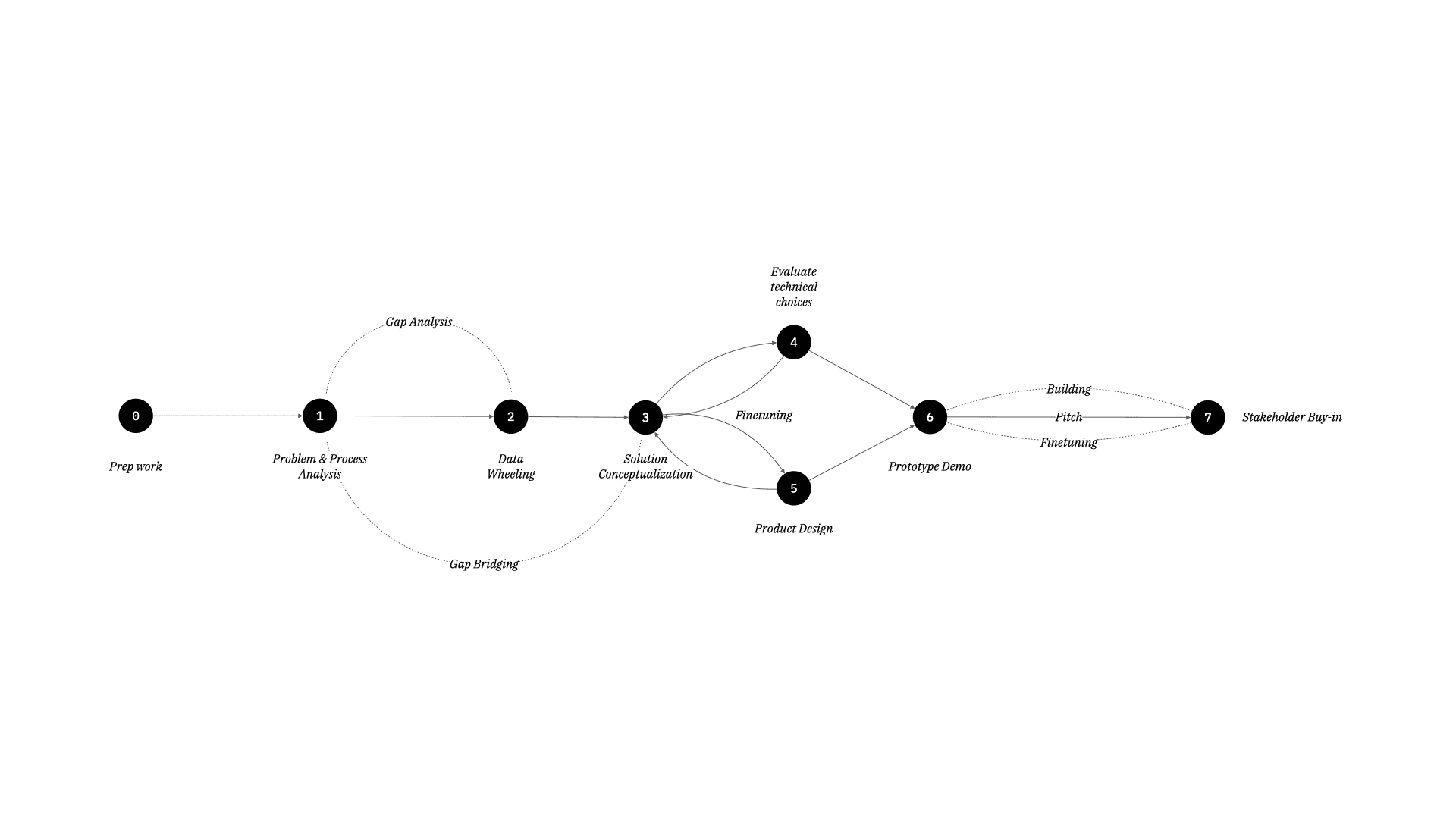
My primary objective was to design a solution that could integrate seamlessly with existing workflows while taking advantage of the emerging technologies. The process unfolded through several critical phases: problem analysis, process analysis, data wheel exercise to understand gaps in the existing system, solution conceptualization, technology integration, thin-slicing, product design, prototype development, customer development with early adopters identification and engagement.
1. Problem & Process Analysis: The initial phase involved an in-depth analysis of the existing clinical trial processes specific to the client and understand the friction points contributing to the delays.
2. Data Wheeling & Gap Analysis: A data wheeling exercise is a collaborative activity designed to assess and improve the entire data lifecycle within a typical organization. We ran this activity primarily to evaluate existing gaps in data collection, cleaning, preparation processes to understand data readiness quotient.
3. Solution Conceptualization: Armed with a fair understanding of the problem, I began conceptualizing a solution that leveraged digital twins and machine learning. The idea was to create a data platform that could act as a central repository, integrating data from various internal and external sources. This platform would utilize agentic AI to autonomously manage data ingestion, cleaning, and preprocessing, ensuring that the data is always up-to-date and ready for analysis (conceptually). The core concept revolved around developing digital twins of the primary consumer market, allowing for real-time simulations and predictive analytics to anticipate and mitigate potential risks.
4. Technology Consideration: For the thin-slice we opted for a cloud-based architecture to ensure accessibility and facilitate collaboration among geographically dispersed teams. Machine learning models were chosen for their ability to analyze large datasets and identify patterns to merge data-sets into intentional data nodes. Additionally, we incorporated natural language processing (NLP) capabilities to enable the platform to understand and interpret unstructured data from research papers, clinical reports, and other textual sources.
5 & 6. Product Design & Prototyping: With the technological foundation laid, the next step was to develop a prototype of the data platform. This involved creating a user interface (UI) that visualized complex data structures in an intuitive manner. Drawing inspiration from familiar applications like Uber’s map-based interface, I designed a "data star" visualization—a spider web-like graphic representing the extensive data network. Each node on the star corresponded to different data sets, color-coded to indicate their sources. This visualization facilitated easy navigation and filtering of data, allowing users to focus on specific cohorts, disease states, or biological targets with a few clicks. The prototype also integrated digital twin simulations, enabling users to run virtual tests on selected drug formulations. By simulating various scenarios, the platform could predict the success rates of different formulations, thereby reducing the need for extensive physical testing. This predictive capability was underpinned by robust ML algorithms trained on historical data, ensuring high accuracy and reliability in the simulations.
7. Stakeholder Engagement and Buy-In: Securing stakeholder buy-in was crucial for the project's success. In the stakeholder buy-in pitch, I articulated the platform's benefits, demonstrating how it could significantly reduce time-to-market and enhance data-driven decision-making. Presenting detailed use cases and ROI analyses helped in gaining the support of executive leadership and key decision-makers to secure internal funding.
Throughout this process, my focus remained on creating a technically solid and scalable solution that could seamlessly integrate with their existing systems while introducing transformative efficiencies. By leveraging digital twins, machine learning, and a centralized data platform, the approach aimed to revolutionize the drug development process, making it faster, more efficient, and more responsive to emerging challenges.
Product Design
In conceptualizing the product design, my goal was to create a user-centric experience that seamlessly integrates vast amounts of data into an intuitive and actionable interface. The centerpiece of this design is the "data star"—a spider web-like visualization that serves as the foundational element of the user interface (UI). Drawing inspiration from platforms like Uber, where maps are central to user interaction, the data star represents the intricate network of data sets that fuel the drug discovery & development process.
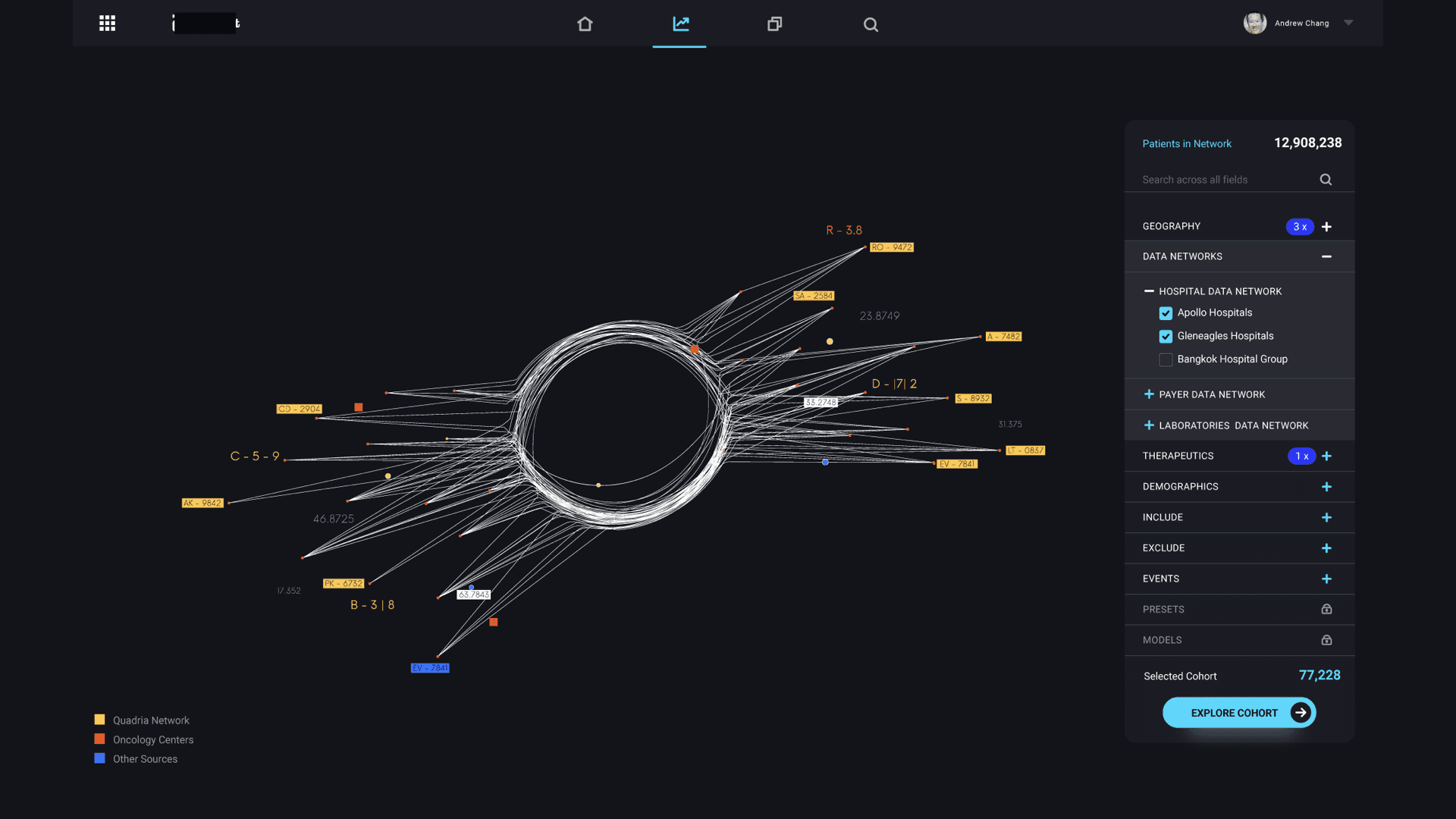
1. Data Star Visualization: The data star is a dynamic visualization tool designed to simplify the complex web of pharmaceutical data into a manageable and navigable format. Each ray emanating from the central hub of the star represents a distinct data set, whether internal (operational and analytical) or external (partnerships and purchased data). These rays merge to form a data node, color-coded to denote their origins, providing immediate visual cues about the data's provenance and other relevant metadata. This organization facilitates quick identification and access to specific datasets, enhancing the platform's usability.
2. Data Integration and Filtering: At the heart of the platform lies its ability to integrate data from diverse sources into a unified repository. The concept of this integration is to achieve robust data ingestion powered by machine learning models and agentic AI in unifying repositories. Users can apply a variety of filters to the data star, enabling them to focus on specific cohorts, disease states, biological targets, market conditions, or potential drug formulations.
3. Digital Twin Transformation: The transformation from data star to digital twin is a pivotal feature of the platform. Once users apply their desired filters, conceptually, the data star undergoes a morphing process, creating a digital twin that simulates the selected cohort's characteristics and behaviors. This digital twin serves as a virtual model for running formulation tests, allowing users to predict acceptance rates and efficacy outcomes without the need for extensive physical trials. The simulation capabilities were conceptually underpinned by advanced machine learning algorithms trained on historical data, ensuring that predictions are both accurate and reliable.
Product Design
4. User Interface (UI) Design: The UI is meticulously crafted to balance complexity with simplicity, ensuring that users can navigate the platform with ease despite the vast amount of data being processed.
5. Workflow Integration: The platform is designed to integrate seamlessly into the existing drug development workflows. Users can initiate data exploration from the discovery phase to identify promising drug candidates quickly. The digital twin simulations provide ongoing insights that inform decision-making and reduce the need for redundant testing.
6. Predictive Analytics and Machine Learning: At the core of the platform's functionality are the predictive analytics and machine learning models that drive data interpretation and simulation. These models analyze historical and real-time data to identify patterns, predict outcomes, and suggest optimal formulations.
7. Customizable Dashboards and Reporting: To cater to diverse user needs, the platform offers customizable dashboards that allow users to tailor their data views according to specific criteria. These dashboards provide real-time updates, monitor progress, track key metrics, and generate insightful reports.
8. Scalability and Flexibility: Recognizing the dynamic nature of pharmaceutical research, the platform is conceptualized with scalability and flexibility in mind. Cloud-based infrastructure could allow effortless scaling to accommodate increasing data volumes and user demands.
In essence, the product design presentation embodies a harmonious blend of advanced technologies and user-centric design principles.



Result
The data platform product pitch presented a transformative idea to revolutionize the pharmaceutical drug development process by integrating machine learning (ML) models and digital twin simulations to significantly reduce the time from discovery to market release and address the core issue of delays in clinical trials.
Although the pitch impressed all the stakeholders we failed to secure funding for this project owing to a couple of issues.
Data quality issues: The organization’s existing datasets suffered from incompleteness, inconsistency, and lack of standardization—undermining trust in any analytics outcome. Metadata was sparse, making it impossible to trace data lineage or validate provenance on critical data sets. Additionally, the absence of standardized ontologies, biomarkers, and chemical compounds led to duplication and misclassified records, creating significant noise for machine learning model training.
Data integration issues: The disparate data sources—ranging from legacy on-prem lab systems and clinical trial databases to third‑party cloud publications—used inconsistent schemas, proprietary formats, and lacked standardization. Building robust ETL pipelines to harmonize, normalize, and validate these inputs would have required substantial data engineering efforts, prolonging the timeline before any tangible ROI could be demonstrated.
Organizational data maturity: Beyond technical obstacles, the company’s low data literacy and absence of a centralized data governance framework undermined confidence in any data‑driven solution. Stakeholders voiced concerns about ownership, stewardship, and the long‑term maintenance burden of a platform that depended on continuous data curation.
Ultimately, these compounding factors created a risk profile that exceeded the organization’s appetite during an already uncertain post‑COVID period. While the pitch showcased a visionary use of machine learning and digital twins to crunch drug development timelines from years to months, the foundational prerequisites—clean, integrated data; robust governance; and a regulatory strategy—were not yet in place. Importantly, our work surfaced critical, previously unrecognized data quality and integration gaps that demand immediate attention before any enterprise‑grade platform can be successfully productized. Addressing these foundational issues is now an urgent priority to unlock the full potential of the organization’s data and pave the way for future innovation.
Reflection
Looking back at the learnings from this journey of conceptualizing and presenting the data platform for the pharmaceutical giant offers valuable insights—
Some things that I'm happy about:
The data star visualization. I feel that the exploded star style visualization truly helps the user to feel the power of data: a universe of relevant data at one's fingertips. Visually and functionally making it easy for the user to select different data nodes to try different combinations to provide interesting correlations. When I presented the UI for the first time and explained the interactions, it was very well received by all the stakeholders involved. There was palpable excitement even.
Here are some post-event reflections:
While the data star visualization was innovative and received very well, one of the early user feedback indicated a need for more enhanced interactivity. If the project was given a green signal on funding, future iterations could've incorporated user-centric feedback to meet functional requirements better to close any gaps in usability. Another area for improvement lies in the integration of real-time collaboration tools.
Facilitating real-time communication and data sharing among team members within the platform could enhance collaborative efforts, leading to more cohesive and efficient workflows. Features such as shared annotations, live data updates, and collaborative dashboards could foster and facilitate high-quality team discussions.
Furthermore, the transition from the hypothesis to the MVP (Minimum Viable Product) stage was curtailed by external uncertainties. To prevent similar scenarios, adopting a more incremental feedback approach could be beneficial. By prioritizing and releasing core functionalities in smaller thin-slices, we could demonstrate quicker value and achieve better alignment with user needs and stakeholder expectations. Carving the right project thin-slice is an art in itself.
LLM & Digital Twin Disclaimer: In the pre-LLM era—"chatbot" and "conversational UI" were the dominant terms used to describe human-machine natural language interactions. I've used "LLM" term here since the core principles of interface design remain largely unchanged. Whether we're invoking a bot, LLM, or AI agent during a task, the fundamental interaction patterns stay consistent. The concept of digital twin existed long ago before they gained popularity around year 2021.
Creative Confidentiality: In the spirit of professional discretion and digital camouflage, some client identities have been subtly transformed into their alter-ego personas. This ninja-like name-swapping applies exclusively to projects completed as an external design mercenary. For all other showcased works, brand and product names remain true to their original, registered identities.
Authenticity Stamp: Every pixel, wireframe, approach, and design concept you'll discover here is 100% crafted by the hands (and occasionally bulletproof caffeinated brain) of Naren Katakam. No design outsourcing, no smoke and mirrors—just pure, unadulterated creative craftsmanship.